By processing audio signals in the time-domain with randomly weighted temporal convolutional networks (TCNs), we uncover a wide range of novel, yet controllable overdrive effects. We discover that architectural aspects, such as the depth of the network, the kernel size, the number of channels, the activation function, as well as the weight initialization, all have a clear impact on the sonic character of the resultant effect, without the need for training. In practice, these effects range from conventional overdrive and distortion, to more extreme effects, as the receptive field grows, similar to a fusion of distortion, equalization, delay, and reverb. To enable use by musicians and producers, we provide a real-time plugin implementation. This allows users to dynamically design networks, listening to the results in real-time.
Examples
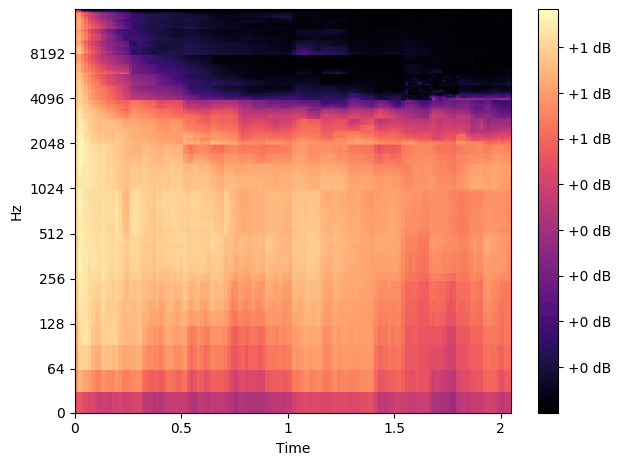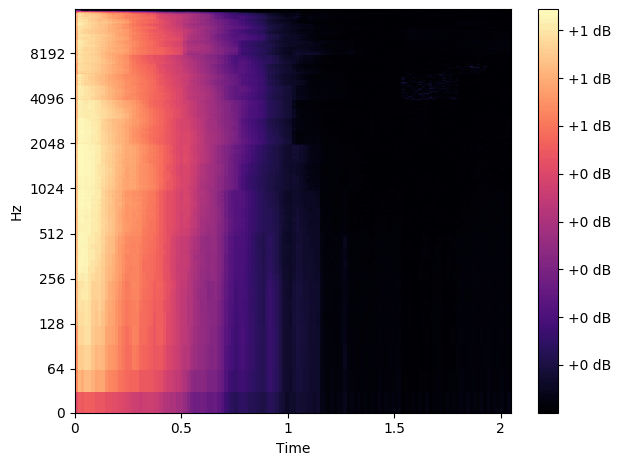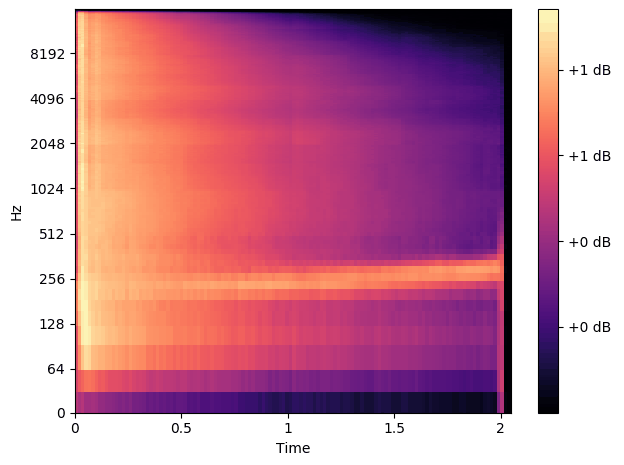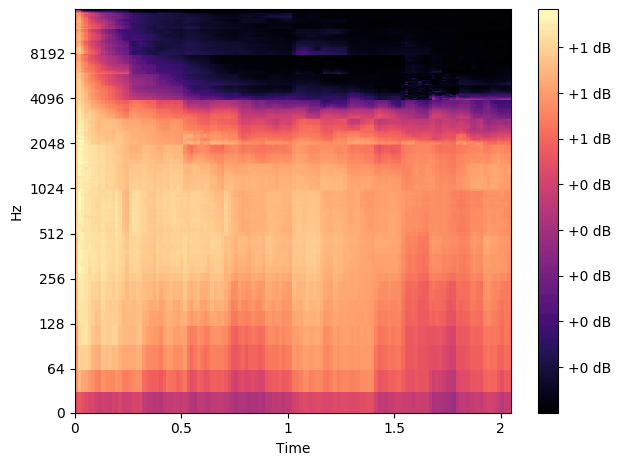
We created a few examples to demonstrate the versatility of the plugin. Each song was created using only the ronn plugin, and no others in Reaper. During these example songs we switch on and off the plugin so you can hear what it's doing.
Indie Rock
This song was made using only the ronn plugin and an electric guitar recorded directly into the interface.
Ambient piano
This song was made using only the ronn plugin and a stereo piano recording.
History
Distortion was first discovered by guitarists when they found that pushing their early vacuum tube guitar amplifiers beyond their operating range produced a warm and fuzzy sound. While distortion is often considered an undesirable artifact, musicians quickly discovered that they could take advantage of these limitations for creative effect. Distortion went on to invade a number of different genres and ultimately became a defining characteristic of rock music. Even today, when many listeners think of the sound of an electric guitar, its a sound dominated by the overdriven characteristic of tube distortion.
From a technical standpoint, the concept of distorting or clipping an audio signal is quite straightforward. As shown in the diagram below, on the right, when the amplitude of the input signal (grey) passes a certain threshold, the amplitude of the output (red) is restricted from increasing further. This seemingly basic process has the effect of introducing additional harmonics to the signal, modifying the timbre and overall characteristics of the original sound. While this effect is considered undesirable in most contexts, such as the voice of a speaker on a phone call, musicians have found applications of this effect that result in more energetic, engaging, and emotionally moving sounds.


After the initial discovery of distortion effects, guitarists and audio engineers began searching for new methods to purposefully induce distortion. In some cases, guitarists even intentionally damaged the speakers or circuitry within their amplifiers to achieve this effect. With the introduction of transistors, dedicated distortion devices could be built to fit in small enclosures. This led to the emergence of the guitar stompbox or pedal, a small enclosure with a dedicated circuit for distorting audio signals. From here, engineers and guitarists with an interest in electronics began experiment with a wide range circuits designed specifically for distortion.
The circuit diagram above shows an example of a diode clipper, one of the most simple circuits of this kind, where a pair of diodes are used to clip the top and bottom of the waveform. Designers found that by using different kinds of circuit components, or varying circuit topologies, they could achieve a wider range of unique distortion timbres. Presently, guitarists and audio engineers are presented with a wide array of digital signal processing devices for applying a seemingly endless number of different distortion effects. While it may seem that all methods of generating distortion has been exhausted, we aim to extend the world of distortion-based effects by applying randomly weighted neural networks to create new kinds of distortion effects.

Design
In our case, we view a neural network as a kind of "circuit" that can distort audio signals. The benefit to this approach is that this "circuit" offers greatly complexity in the space of signal processing possibilities than traditional analog circuits or DSP. Recently, there has been success in emulating the sound of classic distortion effects using neural networks (see here, here, here, and here). These approaches generally train neural networks using a large collection of audio examples that were processed by the original effect. Our approach differs from these approaches, since instead of emulating existing effects, we aim to generate new distortion effects. Interestingly, we found that by randomly setting the weights of different neural networks (without using any data or training at all!) we could achieve interesting effects.
For every neural network architecture (some connection of layers and activation functions), we can randomly set the weights of each layer within the network to produce a different effect. Additionally, we found that by adjusting aspects of the architecture itself, such as adding more layers, changing the intermediate nonlinear functions, of changing the size of each layer, we achieve an even wider range of interesting effects. This changes the interface we use to search for effects. Instead of tweaking the type of effect we achieve by modifying potentiometers within a circuit, or even the design of the distortion circuit or algorithm, we provide controls that let users modify elements of the neural network architecture.

In this work, we focus on the temporal convolutional network (TCN) architecture. This architecture has already been shown to be successful in modeling sequential data across a number of domains, with WaveNet being one of the early examples in the audio domain. More recent works have applied this architecture to a number of different tasks, such as speech denoising and source separation. Here we will adapt this model to provide a platform for processing and distorting audio signals.
The diagram on the left demonstrates how we employ this network in the real-time plugin. Here we shown an example where the network has three layers, we can see that each layer is very simple with only a 1-dimensional convolution, followed by a nonlinear activation function. In the plugin users can control the number of layers, as well as the type of activation function. In addition, other parameters can be adjusted, like the number of channels c, the size of the kernels k, and the dilation growth factor d.
The plugin contains a look-back buffer of length M+N samples, where N samples come from the current block, and M samples come from the past inputs. This M+N sample look-back buffer is then processed by the TCN network (here shown with three layers), to produce an output signal that is N samples, which will be returned to the DAW. The receptive field of the model of the model is shown in the dashed box, which defines how many samples in the buffer are used to generate one output sample. As the receptive field grows (by adding more layers, using larger kernel, or dilations), the look-back buffer will become larger in order to produce an output block of the correct size.
Plugin
The goal of the plugin is to build a C++ implementation that enables users to quickly and easily construct different randomly weighted TCNs, and listen to the produced effects in real-time. This shifts the process of searching for and selecting audio processing effects from the traditional paradigm where users adjust the controls of traditional DSP devices like equalizers and dynamic range compressors, to one where users adjust the architecture of a neural network in order to search for new effects. The TCN can be viewed as a generalized audio effect that can effectively implement a range of transforms, similar to those traditionally employed by audio engineers (e.g. equalization, dynamic range compression, delay, reverberation). In the UI shown below, users have control over a number of architectural aspects of the underlying neural network. By adjusting any of these parameters, the plugin with rebuild the network, in real-time, enabling users to listen to the results fo different architectural adjustments.

Related Projects
Check out our related projects on using neural networks for audio effects!

Paper

Bibtex
@inproceedings{steinmetz2020overdrive,
title={Randomized Overdrive Neural Networks},
author={Steinmetz, Christian J. and Reiss, Joshua D.},
booktitle={4th Workshop on Machine Learning for Creativity and Design at NeurIPS 2020},
year={2020}}